
Unveiling Reasoning Models: Are they ai’s next big leap or just hype?
In September 2024, the AI landscape buzzed with excitement over a new class of models: reasoning models. Unlike traditional large language models (LLMs) that churn out answers based on patterns, models like OpenAI’s o1 and Deepseek-r1 promise to think through problems logically, step by step. The hype was palpable—some hailed them as game-changers, while others raised eyebrows, fearing job disruptions or sci-fi-level AI dominance. But what’s the real story behind reasoning models? Are they truly revolutionary, or just another overhyped AI trend? This blog dives into what reasoning models are, how they differ from traditional LLMs, their performance in evaluations, and what their strengths and limitations mean for AI’s future.
What Exactly Is a Reasoning Model?
Reasoning models represent a significant evolution in artificial intelligence, building on the foundation of traditional LLMs. Standard LLMs, trained on massive datasets of text, predict responses based on learned patterns, often delivering answers without revealing the “how” behind their conclusions. Think of them as gifted students who guess the answer to a math problem but can’t show their work. This approach works well for straightforward queries but falters when tasks demand complex, multi-step logic, leading to errors rooted in overreliance on probability.
Reasoning models, like OpenAI’s o1 or Deepseek-r1, take a more deliberate path. They break down intricate problems into smaller, logical steps, mimicking how humans tackle challenges. Imagine solving a puzzle: instead of guessing the final picture, you sort pieces, test fits, and adjust systematically. These models explore multiple solution paths, discard incorrect ones, and pivot to better approaches, explicitly showing their thought process. This step-by-step reasoning enhances accuracy for tasks requiring layered understanding, such as solving math problems or navigating strategic games.
However, this methodical approach comes at a cost. Reasoning models demand significantly more computational power than traditional LLMs, as they simulate cognitive processes rather than relying solely on pattern recognition. Evaluating their performance also requires new methods, as standard benchmarks may not fully capture their unique capabilities.
Are Reasoning Models Actually Better? How Do We Know?
To gauge the effectiveness of reasoning models, researchers turn to benchmarks—standardized tests designed to measure AI performance on specific tasks. For reasoning models, math-focused benchmarks like MATH-500 and competitive tests like AIME24 and AIME25 are common yardsticks. At first glance, models like Deepseek-r1 appear to outshine non-reasoning counterparts (e.g., Deepseek-v3) on these tests, fuelling claims of superiority.
But the results aren’t as clear-cut as they seem. For instance, reasoning models score higher on AIME24 than AIME25, which is puzzling since human evaluations suggest AIME25 is easier. This discrepancy raises red flags about data contamination—the possibility that models were inadvertently trained on benchmark data, artificially boosting their scores. Such issues undermine the reliability of traditional benchmarks for assessing true reasoning ability.
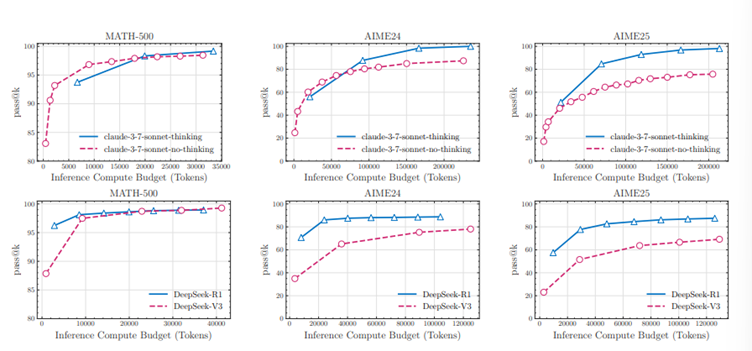
To address this, researchers are exploring alternative evaluation methods that better reflect real-world problem-solving. Benchmarks alone may not tell the full story, especially when training overlaps skew results. This highlights the need for more robust, contamination-free testing environments to accurately measure reasoning models’ capabilities.
Why Puzzles Make Better Tests for Reasoning AI?
Puzzles offer a compelling alternative to traditional benchmarks, as they mirror real-world scenarios where logical, step-by-step reasoning is critical. Unlike math tests that can be gamed through pattern recognition, puzzles demand strategic planning, constraint management, and adaptability—skills central to reasoning models. Four classic puzzles have emerged as go-to tests for evaluating these AI systems:
– Tower of Hanoi: Players move disks between pegs, following rules about disk size and move order. The challenge grows exponentially with each additional disk, testing a model’s ability to plan ahead.
– Checker Jumping: Coloured checkers swap positions on a line through sliding or jumping moves, constrained by strict rules. This evaluates a model’s grasp of sequential decision-making.
– River Crossing: Actors (e.g., a farmer, wolf, and cabbage) must cross a river with constraints, like ensuring certain actors aren’t left together unsupervised. This tests constraint satisfaction and logical prioritization.
– Blocks World: Blocks are rearranged from an initial setup to a goal configuration, moving only one block at a time from stack tops. This assesses a model’s ability to strategize over multiple steps.

These puzzles emphasize accuracy and goal achievement over mere optimality, making them ideal for probing a model’s reasoning depth, planning skills, and ability to generalize across complex scenarios.
How Do Reasoning Models Stack Up in Puzzle Tests?
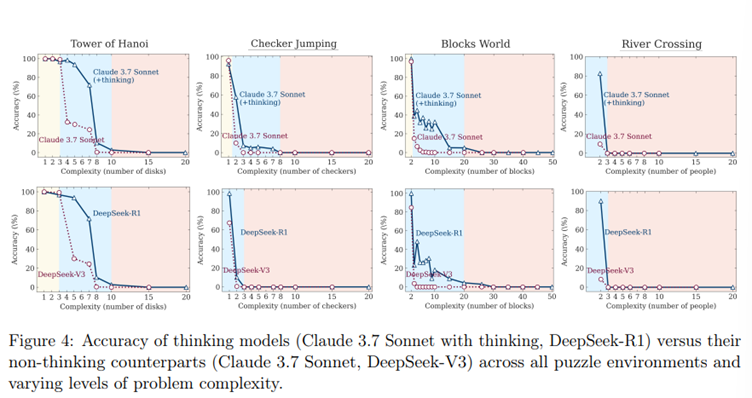
Testing reasoning models in puzzle environments reveals a nuanced picture of their strengths and limitations. Performance varies across three complexity regimes compared to non-reasoning LLMs:
1. Low Complexity: For simple puzzles, non-reasoning models often match or even outperform reasoning models. At this level, problems are straightforward enough that pattern-based answers suffice, diminishing the need for stepwise logic.
2. Medium Complexity: This is where reasoning models excel. Their ability to break problems into logical steps and explore solution paths gives them a clear advantage, solving tasks that stump traditional LLMs. For example, in a River Crossing puzzle, they methodically test combinations to ensure constraints are met.
3. High Complexity: As puzzles become highly complex, both reasoning and non-reasoning models struggle, with performance dropping to near zero. Reasoning models delay this collapse slightly, but they too hit a wall, unable to scale their cognitive effort effectively.
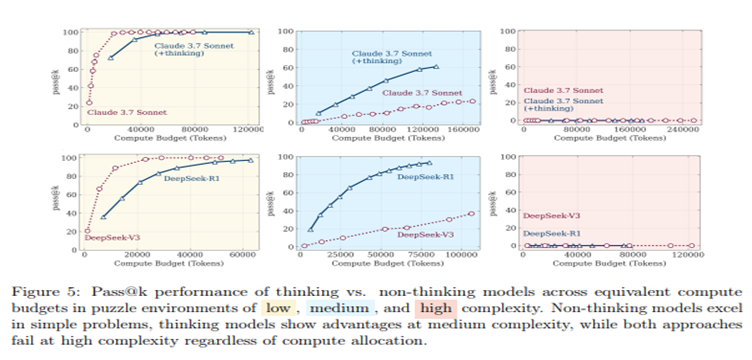
Interestingly, as problem complexity increases, reasoning models initially ramp up their “thinking” effort, exploring more paths. But beyond a certain threshold, they paradoxically reduce their reasoning, even when problems demand deeper analysis. This suggests a fundamental limit in current model architectures, where cognitive resources fail to keep pace with escalating complexity.
The Hidden Flaw: Overthinking and Collapse
One surprising drawback of reasoning models is overthinking. On simpler puzzles, they may find the correct solution early but continue exploring incorrect paths, wasting computational resources and reducing efficiency. Imagine a chess player over analysing a basic move, second-guessing a straightforward strategy. For moderately complex tasks, reasoning models often explore wrong solutions before converging on the right one, which is more efficient but still imperfect.
At high complexity, the models enter a collapse mode, failing to produce correct solutions altogether. This behaviour points to a critical challenge: current reasoning models struggle to allocate cognitive effort strategically, either overcomplicating simple tasks or underperforming on tough ones. Addressing this will require architectural innovations to better balance exploration and decision-making.
What Does This Mean for the Future of Reasoning Models?
Reasoning models like Deepseek-r1 and OpenAI’s o1 mark a pivotal step toward AI that doesn’t just mimic language but tackles problems with human-like logic. Their ability to break down complex tasks opens doors to applications like automated planning, scientific discovery, and strategic decision-making. For instance, imagine an AI that can optimize supply chains by reasoning through logistical constraints in real time.
Yet, these models aren’t a cure-all. They shine in moderately complex scenarios but share limitations with traditional LLMs when problems become too intricate. Overthinking and performance collapse underscore the need for smarter architectures that can scale reasoning efficiently. Additionally, flawed benchmarks highlight the importance of developing robust, real-world-inspired evaluation methods, like puzzle-based tests.
This section includes insights on potential applications, added by ChatGPT based on general AI trends observed online.
Wrapping Up: A Step Forward, Not a Leap
Reasoning models are a promising stride toward AI that thinks more like humans, methodically working through problems with logical precision. They outperform traditional LLMs in tasks requiring multi-step reasoning, particularly at moderate complexity. However, their tendency to overthink simple problems and collapse under high complexity reveals significant room for improvement.
To unlock their full potential, researchers must refine model designs to manage cognitive effort strategically and develop better evaluation methods that reflect real-world challenges. For now, reasoning models are an exciting milestone, not a final destination. They bring us closer to true machine intelligence but remind us that the journey is far from over.
Key Takeaway: Reasoning models offer a glimpse of AI’s problem-solving future, but overcoming their limitations will require innovative architectures and smarter testing environments.
For a deeper dive, check out the research paper inspiring this discussion: https://arxiv.org/pdf/2506.06941
Conclusion
Reasoning models like OpenAI’s o1 and Deepseek-r1 introduce a new era of AI that prioritizes logical, step-by-step problem-solving. They excel in moderately complex tasks, outperform traditional LLMs in strategic puzzles, but struggle with overthinking and collapse on highly complex problems. While promising, they highlight the need for better architectures and evaluation methods to fully realize AI’s reasoning potential.
About the Author
Bharath S L is an AI Intern at 4i apps solutions, working with the PD Gen AI team, with a multidisciplinary background in Artificial Intelligence and systems engineering. His work focuses on the development of generative AI applications, particularly in the areas of Retrieval-Augmented Generation (RAG) and natural language – SQL interfaces. He explores the intersection of AI, backend infrastructure, and real-world domains such as healthcare and enterprise automation.






